I’ve been experimenting with Claude Code to write research code for several months now. When I last wrote about this, I was worried that I wouldn’t feel in control of my own code, that bugs would creep in, and for a general decline in my own (coding) expertise and even enjoyment.
To my own surprise, I actually quite liked it - although there is a trade-off. I’ll first explain my workflow so far and then share my overall experience and some thoughts.
How it works
Claude Code simply runs in a terminal window and needs permission to read/write certain files and execute certain shell commands (eg create a new file, run a python script, run a search query, install a package, etc). You can chat directly in the terminal and see Claude work in real-time, showing its planning, reasoning, file edits, executed shell commands, etc.
I started a fresh codebase and used Claude from the start. This felt like a really nice alternative to finding a repo from a published paper - in my experience these can be hard to read, incomplete, and sometimes even buggy. Also, starting from scratch gives me full control over the code and its design.
Workflow: a team member
The workflow reminds me most of working in a software engineering team.
The first step is working out a high-level system design and architecture, potentially brainstorming with Claude, and then to refine a new task: a feature, bug fix, refactor, etc. A task shouldn’t be too small (changing a variable name), but also not too big (totally refactoring a big complex codebase). An example task might be to create a generation pipeline or LLM-as-a-judge evaluation with an external API.
I then ask Claude to present a plan and iteratively refine it “together”. I can ask it to work on a new git branch and submit a pull request when it’s done - just like a team member might. At this point I can go for a walk while Claude gets to work. (Or watch it work in real-time, or even start another Claude instance to work on a different tasks in parallel.). It’s really insane how often Claude understands exactly what I mean, even when I’m vague, and how the code is high quality with good design patterns, without having to specify everything in detail.
Now, this next step is really important: I carefully review each line of code as if it were a pull-request made by a team member. This really makes it feel like my own code. Finally, I either make changes manually or give Claude a list with desired changes. Note how proper version control is absolutely essential, since you want to be able to clearly see the changes and easily revert them.
The workflow really feels iterative and interactive, rather than just typing in a single prompt. That’s also a matter of style and how much context/detail you provide initially.
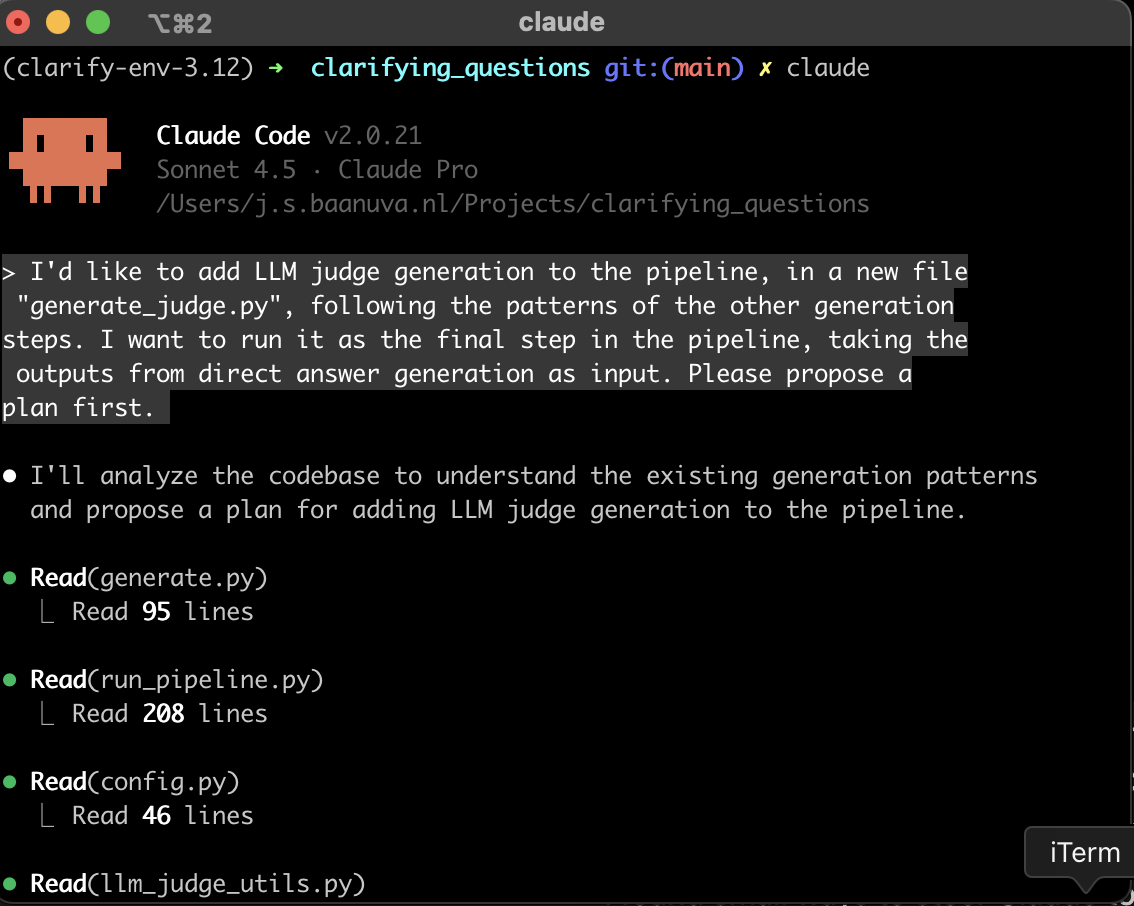 |
|---|
| The CLI interface of Claude Code. At this point I built a pretty big codebase already. The task I describe is relatively small, but still spans several files and includes various design decisions. I added another screenshot from further in the “conversation” at the bottom of this post. |
Mistakes
Although the code is of really high quality, Claude makes mistakes. As I will undoubtedly make mistakes in my own code - at least during development. I think it’s crucial to be able to judge whether Claude’s code is good or bad, and have an intuition for where to expect issues (e.g., complicated indexing logic during batching). Careful reviewing is so critical because small, invisible mistakes in scientific code can have a big impact on experimental results.
I found small ways to steer Claude towards better code, like asking it to review its own code or find bugs, or by linking to a page of official documentation for some framework that I want it to use.
Interestingly, because the process is so much easier and faster, I noticed that I’m more inclined to use good software engineering practices and design my code such that minimizes the possibility for bugs. For example, unit and integration tests.
Unit and integration tests
After working as an ML engineer I’ve always found it strange that we generally never write tests in NLP/AI research. To some extent this makes sense: research code changes rapidly; you’re often writing it alone; writing and maintaining tests is time consuming; and it can be hard to write meaningful tests that mock or run big, stochastic models. Still, I think it’s really useful to include tests.
Creating - and particularly maintaining - unit/integration tests with Claude Code is so much faster. This gave me more confidence in my codebase. A very cool thing is that, since Claude can run anything, it can run these tests too, iteratively improving its own code similar to how I would work myself.
One caveat: tests still need to be designed and reviewed with care. Just saying “write tests for this script/function” can result in a lot of tests that didn’t quite capture what was important to me. Similarly, just saying “fix these failing tests” makes Claude either adapt the test to the new code or vice versa, and the difference can be crucial.
In this sense, tests can also give a false sense of security.
Vibe coding non-crucial tools
My strategy so far is very hands-on, which I think is (at least for now) important for core research code. I wouldn’t feel comfortable using Claude to write core research code in a codebase that I’m not familiar with, or to create everything at once without breaking it up in smaller tasks that I carefully describe and review. Besides, research is iterative anyway and you often end up with something different than you set out to do initially, which makes it hard to specify everything perfectly in the beginning.
I used a different strategy to build a web interface in pure html/css/js to visualise individual records from a dataset with model generations, evaluation metrics, uncertainty metrics, and search and filtering to navigate. I let Claude build and maintain the entire tool through prompting alone - I guess I’d call this vibe coding - without looking at or changing single line of code. It worked remarkably well.
This is a nice example of something extra that I wouldn’t have built without Claude, and I feel comfortable not understanding the code since it’s not part of my experiments.
My overall experience
Surprisingly, I actually quite enjoyed this new process. I’m stuck less often; I still experience the joy of writing good code; I still feel on top of everything. Things that would have taken me several hours to implement are now done in a matter of minutes.
However, there is a trade-off. Letting Claude work on bigger, more complex tasks autonomously leads to faster progress, but also less control, understanding, and trust - so in the long run, perhaps less progress. It depends on the risk you’re willing to take and the extent to which you care about the specifics of the implementation and all the little choices involved.
Going from nothing to something, like adding new features in a fresh codebase, works like magic. Just like finding and fixing bugs, and asking language or framework related questions (stackoverflow style). It led to much faster experimentation and helpful tools. Also, it’s somehow easier for me to be satisfied with code that I did design but didn’t write: I don’t get pulled into prematurely optimizing for elegance, generality, or efficiency as much, and it reduces cognitive effort not having to think about variable names or function structures, etc.
However, for more subtle, complex changes, especially across a larger, complex codebase (like big refactors), I sometimes spent more time correcting Claude than I would’ve needed to write it myself. That’s really annoying. Also, problems are often more complicated than you initially think, and working through them give a different perspective on the solution or even my end goal. Offloading this to a coding agent that autonomously decides how to tackle those problems is risky if the details matter (which they often do in research code).
I guess part of the skill of using a coding agent is to know how and when to use it.
Productivity
Does it really make me more meaningfully productive? For some tasks, most definitely. And in this specific case of setting up a new codebase, especially in the beginning, it really did feel that way.
However, I could be fooling myself. For example, this study found that experienced developers felt more productive using AI but were in fact slower. Perhaps coding agents give a “feeling of productivity” or “reduction of cognitive effort” rather than actually supporting more or faster long-term progress. Or perhaps it’s just the initial learning curve for this kind of tool. Maybe coding agents turn out to be more about code quality rather than quantity - it’s hard to say. They haven’t been around long, and I suspect they will keep improving over time.
Closing thoughts
I’m still critical about many other aspects. For example, sending my research code to a commercial company’s servers. Or pricing: it’s relatively affordable right now (about $20/month), but pricing is bound to go up, which could make over-reliance a (financial) problem and prohibit access for researchers that can’t afford it. Energy consumption of these tools is also concerning.
However, can we AI researchers use coding agents to help us write scientific code responsibly? I think so, yes. But it’s the responsibility of the researcher to carefully design, review, adapt, and own the resulting code. I think you need to be able to write and understand everything yourself to be able to use it responsibly (and effectively) for complex tasks, as to recognize good from bad design/architecture/code/tests/etc, and spot mistakes. Small mistakes in scientific code can have a big impact on experimental results.
I do think it’s useful and important (and fun) as an AI researcher to experiment with and understand these tools, and I will continue to. Right now, coding agents somehow feel both like a radical change in how to write code, but also like just another tool.
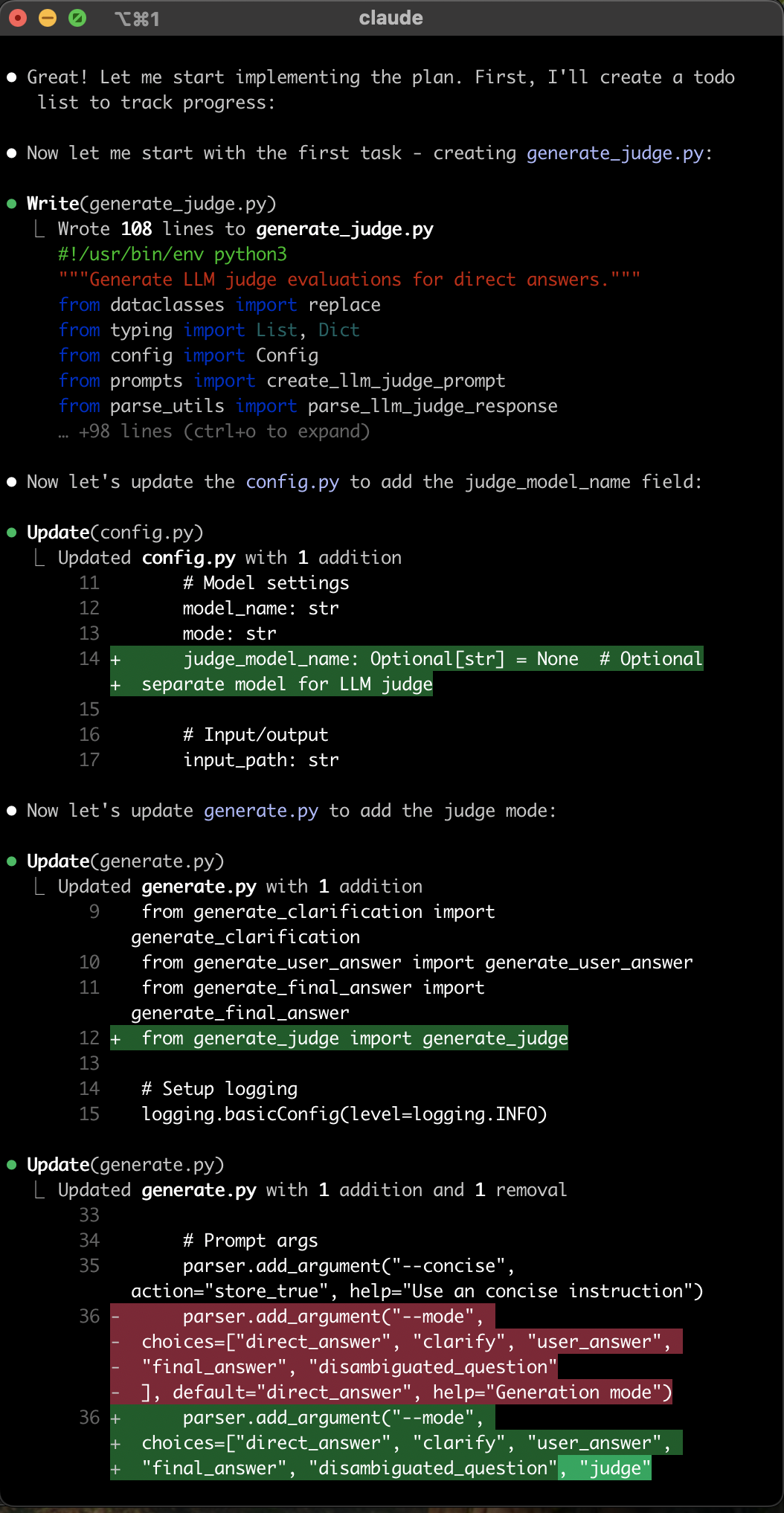 |
|---|
| After a few back-and-forths about the plan and giving my approval, Claude Code starts creating and editing files. There’s too much text to show everything, so this is just a tiny snippet of the entire chat. |